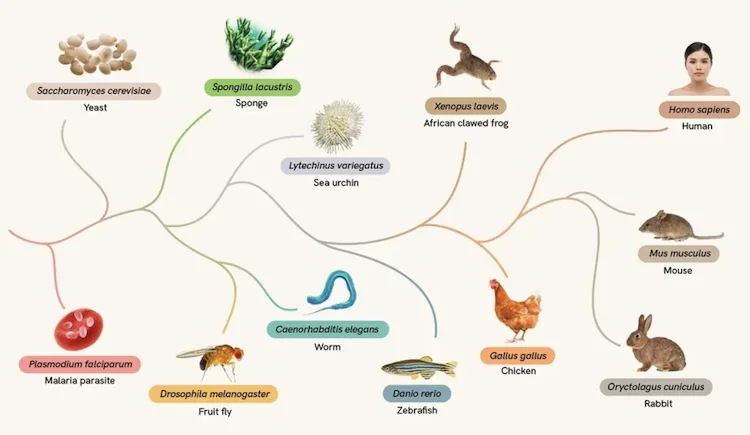
もし、実験室で細胞を培養する代わりに、コンピュータ上で「仮想の細胞」を動かし、病気の謎を解き明かせるとしたら?まるでSFのような世界が、いま現実のものになろうとしています。その壮大なプロジェクトに向けた重要な一歩として、15億年にわたる生物の進化の歴史を学習した驚異的なAIモデルが誕生しました。私たちは、細胞の挙動を予測し理解するための仮想細胞モデルの構築を目指しています。15億年の進化にまたがる12種の生物の細胞が、その学習に用いられました。

生物医学研究における根本的な課題は、人体内の個々の細胞が持つユニークな役割、機能、そして挙動についての理解が限られていることです。チャン・ザッカーバーグ・イニシアチブ(CZI)は、ヒト生物学の内部構造を解明し、人間の病気の負担を大幅に軽減するためのブレークスルーを加速させる、4つの壮大な科学的挑戦に根差した主要な生物学的問題の解決に取り組んでいます。これらの挑戦の一つが、今後数年間でAIベースの仮想細胞モデルを構築し、細胞の挙動を予測・理解することです。これは、様々なスケール、時間枠、科学的モダリティにわたって生物学をシミュレートするものです(Bunne et al, Cell 2024参照)。
仮想細胞構築への道のりにおいて、CZIはCZ CELLxGENEに集約されたような細胞アトラスに投資し、そのデータ生成ロードマップとして「10億細胞プロジェクト」を優先させ、大規模な単一細胞測定を細胞情報の主要な源として位置づけてきました。これらのリソースを活用する重要なステップとして、私たちはシングルセルモデル「TranscriptFormer」をリリースできることを誇りに思います。これは、そのような細胞アトラスをインタラクティブなモデルに変えるための次なる一歩です。TranscriptFormerは、進化と発生を通じて多様な種の細胞アトラスを基に構築されています。これは仮想的な実験器具として使用でき、研究者はプロンプトとして質問を投げかけることで単一細胞データを扱い、実験室で実験を行う前にin-silico(コンピュータ上)で仮説を検証することができます。
広大な進化的距離を超えて生物学を一般化できる生成モデル
何十億年もの進化の歴史にわたる細胞を理解することは、研究者が細胞とその機能に関する新たな洞察を発見するのに役立ちます。TranscriptFormerは、単一細胞トランスクリプトミクスのための初の生成的な多種モデルです。これは12の異なる種からなる1億1200万個の細胞で学習され、15億年の進化をカバーする、最も進化的に多様な学習データコーパスを代表しています。学習データは、CZ CELLxGENE、Tabula Sapiens、z、およびその他の公開されているデータセットから供給されました。
TranscriptFormerは、細胞がどのように機能するかを発見するための生物学的モデルにおける重要な進歩を表しています。それは、異なる組織、感染や病気のような異なる状態、そして特に種を超えて細胞がどう機能するかを理解する助けとなります。これは仮想細胞モデルへの重要な一歩であり、時間のかかる実験室での実験ではなく、計算上の実験が発見プロセスを加速させ、研究上の問いに対するより即時のフィードバックを得るのに役立ちます。
TranscriptFormerは、細胞種、ドナー、種などのラベル付きデータを含めることなく、学習データに含まれていない種でさえも、種を超えて細胞を分類し、疾患状態を特定する上で最先端の性能を示します。これは、種を横断する学習データセットの初の体系的な比較であり、分布外の種の細胞型分類などのタスクにおいて、同等のモデルを上回ります。
TranscriptFormerのようなモデルは、進化と保存された遺伝子発現パターンのプリズムを通して見た、私たちの根底にある生物学の理解に近づくのを助けることができます。そして私たちは、その情報を利用して、将来、病気をより良く理解し、治療し、さらには予防することができます。
研究者はTranscriptFormerを使用して、異なる種類の細胞が何であるか、細胞が病気であるかどうか、そして遺伝子がどのように相互作用するかを予測できます。その名前は、トランスフォーマーベースのアーキテクチャと、細胞内の遺伝的指示のRNAベースのコピーである細胞転写産物(トランスクリプト)に対する生成的 dla学習に由来しています。
私たちが新しいプレプリントで詳述している
TranscriptFormerは、細胞の挙動を予測し理解するためのAIベースの仮想細胞モデルを構築するという私たちの目標に向けた重要な一歩です。
研究者がTranscriptFormerでできること
TranscriptFormerファミリーの生成モデルは、進化と発生を通じて様々な種の細胞アトラスで学習され、多様な下流タスクに使用される出力を生成します。
1. 進化的に離れた種(分布外の種を含む)の細胞タイプを予測する
TranscriptFormerは、アカゲザルやマーモセットのような、これまで見たことのない種の細胞タイプを特定し、遺伝子発現パターンや生物学的パターンを種を超えて翻訳することができます。また、精子形成のケーススタディで示されているように、関連種間でラベルを転移させることもできます。これは、ある種の発見がヒト細胞に翻訳される可能性があるかどうかを予測する健康研究に役立ちます。また、まだマッピングされていない種の細胞タイプの注釈付けを可能にし、将来的には限られた細胞しかサンプリングできないアトラスの完成にも繋がります。
2. 疾患状態を予測する
TranscriptFormerは、特定の疾患についてファインチューニングや学習を行うことなく、感染や疾患状態に関連する細胞タイプや遺伝子活性を発見するために使用できます。COVID Lungアトラスにおいて、SARS-CoV-2感染細胞を非感染細胞から識別するタスクでベースラインモデルを上回り、感染が不明または厳密に特定できないデータセットでどの細胞が感染している可能性があるかを予測する有用性を示しました。
3. プロンプトによる遺伝子間相互作用の予測
TranscriptFormerを生成モデルとしてプロンプト入力することで、特定の組織や生物内の特定の細胞タイプでどの遺伝子が共発現するかを特定するなど、遺伝子が異なる細胞タイプや条件下でどのように連携して機能するかをシミュレーションできます。これにより、モデルが学習した細胞アトラスに直接含まれる知識を探ったり、その範囲外の予測を行ったりすることができます。
次のステップ
TranscriptFormerは、細胞の挙動をより良く予測し理解することを目指す一連のモデルの第一歩です。私たちはこのモデルを繰り返し改良し続けると共に、顕微鏡画像とトランスクリプトミクスのような複数のモダリティを組み合わせた新しいモデルを開発していきます。
私たちは、CZIおよび研究コミュニティによって生成されたキュレーション済みのモデル、データセット、その他のリソースを、科学者が協力、反復、発見のためにオープンに利用できるようにすることにコミットしています。この仮想細胞を構築する取り組みは、生物医学研究、疾患診断、治療法開発に幅広い応用をもたらし、科学者を今世紀末までにすべての病気を治癒、予防、管理するという目標に近づけるものと信じています。